C2C brings together Google Cloud customers from around the globe to share ideas, insights, and strategies in a space that’s built for authentic, peer-to-peer cloud conversation. Whether you’re looking to overcome challenges, drive business growth, or dive into technical details, you can tap into the collective wisdom of cloud professionals like you.
Explore upcoming digital events, in-person meetups, and opportunities to engage with cloud leaders.
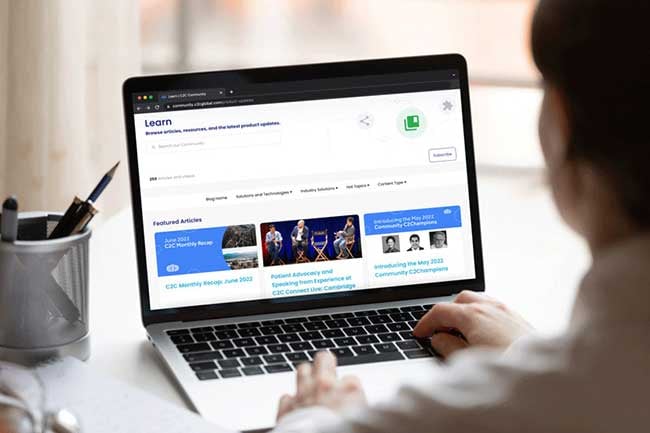
Resources
Find the latest news, product updates, case studies, and more to dive into the Google Cloud ecosystem.
Insights
Discover C2C-exclusive research on development trends and technology usage among members.
Stories from our members
Hear what people love about C2C.
“
I've met so many interesting people at the C2C events! It's truly an inspiring Google Cloud-centered community.
Chanel Greco, Saperis
“
👍 Super thanks a ton C2C, for creating a continuous learning culture within our great Google Cloud Community. Today's session on "Vertex AI with Priyanka Vergadia, was vibrant. 🎉 💙 It is a deeply thoughtful and compelling conversation, I learned a lot. Thanks a ton.
Kumar Chinnakali, Capgemini
“
After just one C2C event, I made connections in the double figures who I still keep in touch with. It's a vibrant community for partners and customers alike. There is a very natural atmosphere and the content is very engaging and informative.
Simrin Gill, Cobry
“
I enjoy using C2C to learn about GCP and the art of the possible.
Jimmy Arbelaez, FRONTdoor Collective
“
C2C is a go-to place for the Google cloud community events and it’s one of the active forum that engages in real time, all the time.
Lakshmikanth Rajamani, Iconic Consulting, AB
“
C2C connected me to the Google Cloud PM in charge of the product we are using. I am going to be sure to attend all the C2C events that I can and tell my peers.








.jpg?width=532&height=532&name=Ethan%20Lo%20(2).jpg)


































.jpg?width=1200&height=800&name=JPEG%207%20(1).jpg)
.jpg?width=1200&height=800&name=JPEG%205%20(3).jpg)
.jpg?width=1200&height=800&name=JPEG%206%20(1).jpg)
.jpg?width=1200&height=800&name=JPEG%202%20(2).jpg)

